个人总结:该文章根据传统Raft严格守序确认和提交以达到协议正确性的特性,提出现有硬件技术和数据库技术支持乱序提交,而守序确认和提交在事务繁忙时会造成一定的时延,尤其是当IO深度变长时,所以基于Raft提出了乱序确认和乱序提交的ParallelRaft协议,该协议通过在leader选举阶段新增加一个合并阶段来保证乱序确认下Leader的完整性,而对于乱序应用apply(提交)下状态机的一致性,作者通过设计一个look-behind-buffer来解决,保证了冲突日志只能按严格的顺序apply。最后,作者还提出了一种快同步的catch-up方法,帮助离线follower快速与leader同步状态,进一步提高了效率。
| Commit | checkpoint | pruned |
|---|---|---|
| 将日志条目应用提交,Raft保证提交的条目是持久的,并且最终将由所有可用的状态机执行。 什么时候可以提交? 一旦创建日志条目的leader在大多数服务器上复制了日志条目,日志条目就会被提交。 | 每次apply后标记一个checkpoint,checkpoint之前的日志条目都是被committed的 | (可能) 如果一个日志条目在应用到状态机之前,发现它与后续的日志条目存在冲突,那么这个日志条目可能会被丢弃,这个过程可能被称为”pruning” |
Abstract摘要
PolarFS是一个分布式文件系统,具有超低延迟和高可用性,专为POLARDB数据库服务而设计。PolarFS在用户空间中使用轻量级网络堆栈和I/O堆栈,充分利用了RDMA、NVMe和SPDK等新兴技术。通过这种方式,大大降低了PolarFS的端到端延迟。(PolarFS是一个为POLARDF数据库设计的分布式文件系统)
为了保持副本一致性,同时最大限度地提高PolarFS的I/O吞吐量,我们开发了ParallelRaft,这是一种源自Raft的共识协议,它通过利用数据库的无序I/O完成容忍能力来打破Raft的严格序列化。ParallelRaft继承了Raft的可理解性和易于实现性,同时为PolarFS提供了更好的I/O可扩展性。(ParallelRaft是一个为PolarFS设计的无序提交Raft共识协议)
Introduction引言
然而,数据存储技术仍在快速变化,因此当前的云平台难以充分利用新兴的硬件标准,如RDMA和NVMe SSD。例如,一些广泛使用的开源分布式文件系统,如HDFS[5]和Ceph[35],被发现具有比本地磁盘高得多的延迟。当使用最新的PCIe固态硬盘时,性能差距甚至可以达到数量级。直接在这些存储系统上运行的关系数据库(如MySQL)的性能明显低于具有相同CPU和内存配置的本地PCIe ssd。为了解决这个问题,云计算供应商,如AWS、谷歌云平台和阿里云,提供了实例存储,但实例存储也有问题,不适用于大型数据库和高级云数据库服务。
本文介绍了分布式文件系统PolarFS的设计和实现,该系统采用以下机制提供超低延迟、高吞吐量和高可用性。首先,PolarFS充分利用RDMA和NVMe SSD等新兴硬件的优势,并在用户空间实现轻量级网络堆栈和I/O堆栈,以避免陷入内核并处理内核锁。其次,PolarFS提供了一个类似posix的文件系统API,它打算被编译到数据库进程中,取代操作系统提供的文件系统接口,这样整个I/O路径就可以保留在用户空间中。第三,PolarFS数据平面的I/O模型也被设计为消除关键数据路径上的锁和避免上下文切换:所有不必要的内存副本也被消除,同时DMA被大量用于在主存和RDMA NIC/NVMe磁盘之间传输数据。有了所有这些特性,PolarFS的端到端延迟已经大大降低,非常接近SSD上的本地文件系统。
一旦Raft应用于PolarFS,我们发现Raft在使用超低延迟硬件(例如NVMe SSD和RDMA,其延迟在几十微秒量级)时严重阻碍了PolarFS的I/O可扩展性。因此,我们开发了ParallelRaft,这是一种基于Raft的增强共识协议,它允许乱序日志确认、提交和应用,同时让PolarFS遵守传统的I/O语义。利用该协议,极大地提高了PolarFS的并行I/O并发性。
背景
RDMA是一种host-offload, host-bypass技术,允许应用程序(包括存储)在它们的内存空间之间直接做数据传输。具有RDMA引擎的以太网卡(RNIC)–而不是host–负责管理源和目标之间的可靠连接。使用RNIC的应用程序之间使用专注的QP和CQ进行通讯:
- 每一个应用程序可以有很多QP(queue pair)和CQ(完成队列)
- 每一个QP包括一个SQ(发送队列)和RQ(接收队列)
- 每一个CQ可以跟多个SQ或者RQ相关联
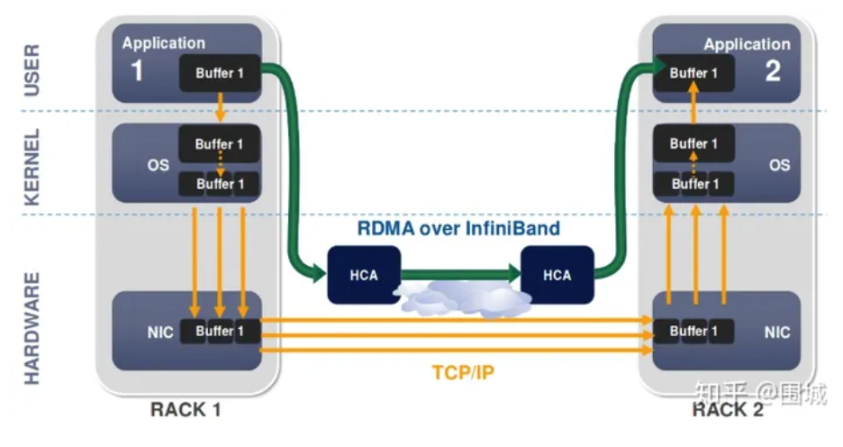
传统Raft存在的问题:Raft被设计为高度序列化的简单性和可理解性。它的日志不允许在leader和follower上都有空洞,这意味着日志条目由follower确认,由leader提交,并按顺序应用到所有副本。因此,当写请求并发执行时,它们将按顺序提交。在所有前面的请求被持久地存储到磁盘并得到响应之前,不能提交和响应队列尾部的请求,这会增加平均延迟并降低吞吐量。我们观察到,当I/O深度从8增加到32时,吞吐量下降了一半。
Raft不太适合使用多个连接在领导者和追随者之间传输日志的环境。当一个连接阻塞或变慢时,日志条目将无序地到达follower。换句话说,队列前面的一些日志条目实际上会比后面的日志条目晚到达。但是Raft跟随者必须按顺序接受日志条目,这意味着它不能发送一个确认来通知leader后续的日志条目已经被记录到磁盘上,直到之前丢失的日志条目到达。此外,当大多数follower因为缺少日志条目而被阻止时,leader会陷入困境。然而,在实践中,对于高度并发的环境,使用多个连接是很常见的。我们需要修改Raft协议以适应这种情况。
在事务处理系统(如数据库)中,并发控制算法允许以交错和乱序的方式执行事务,同时生成可序列化的结果。这些系统自然可以容忍由传统存储语义引起的乱序I/O完成,并自行处理以确保数据一致性。实际上,像MySQL和AliSQL这样的数据库并不关心底层存储的I/O序列。数据库的锁系统将保证在任何时候,只有一个线程可以在一个特定的页面上工作。当不同的线程并发地在不同的页面上工作时,数据库只需要成功执行I/ o,它们的完成顺序无关紧要。因此,我们利用这一点放宽Raft在PolarFS中的一些约束,开发出更适合高I/O并发性的共识协议。
作者将ParallelRaft分成更小的部分:日志复制、leader选举和catch up来介绍。
1.无序日志复制
Raft在两个方面进行序列化:(1)leader向follower发送日志条目后,follower需要对其进行确认,告知该日志条目已被接收并记录;这也隐式地表明已经查看并保存了前面的所有日志条目。(2)当leader提交一个日志条目并将该事件广播给所有follower时,它也承认之前所有的日志条目已经提交。ParallelRaft打破了这些限制,乱序地执行所有这些步骤。因此,在ParallelRaft和Raft之间有一个基本的区别。在ParallelRaft中,当一个条目被识别为已提交时,并不意味着之前的所有条目都已成功提交。为了保证该协议的正确性,我们必须保证:(1)如果没有这些串行限制,所有提交的状态也将与经典的理性数据库所使用的存储语义一致。(2)所有已提交的修改不会在任何角落丢失。
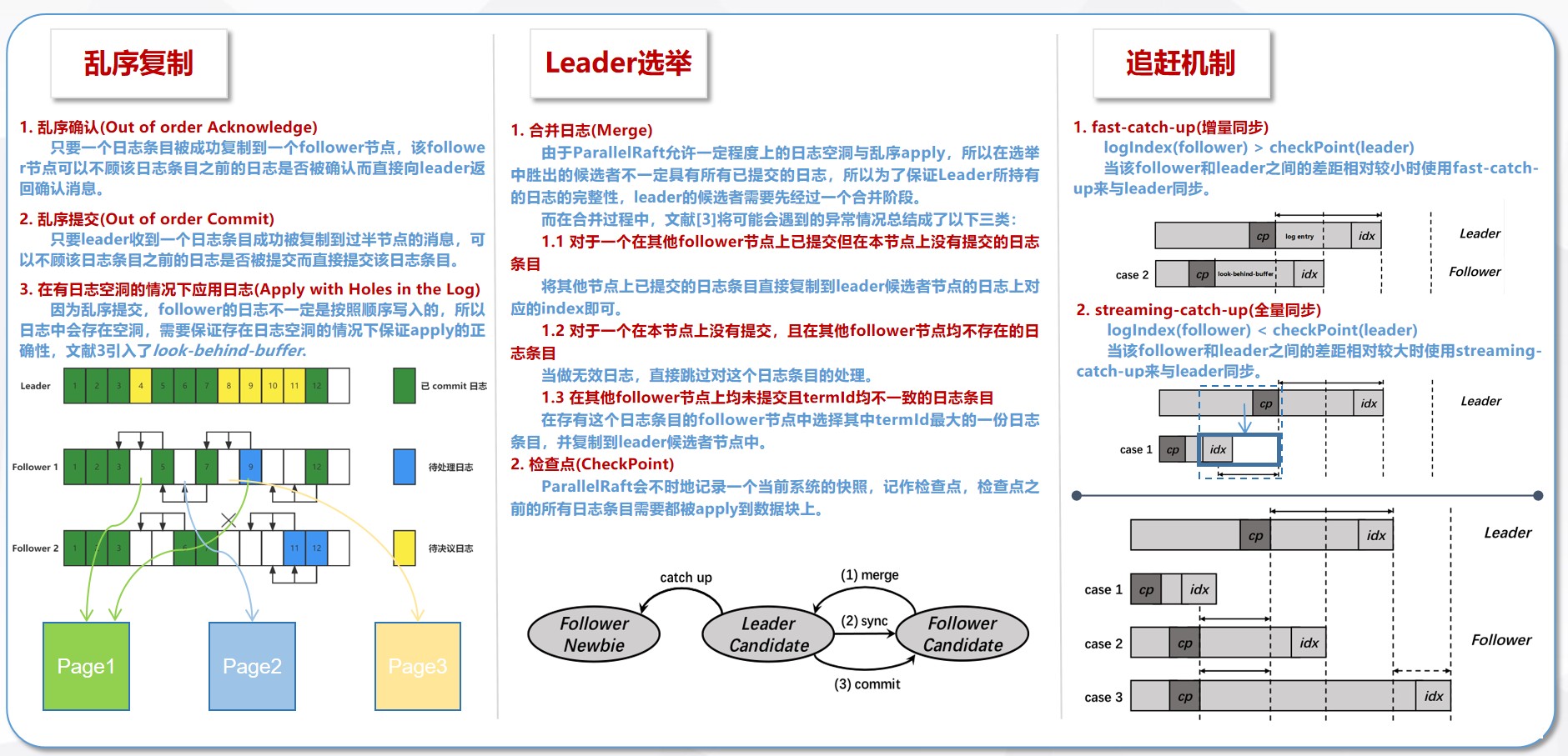
ParallelRaft的乱序日志执行遵循以下规则:如果日志条目的写入范围彼此不重叠,则认为这些日志条目没有冲突,并且可以以任何顺序执行。否则,冲突的条目将在到达时按照严格的顺序执行。通过这种方式,新数据永远不会被旧版本覆盖。ParallelRaft可以很容易地知道冲突,因为它存储了任何未应用的日志条目的LBA(Logical Block Address,逻辑块地址)范围摘要。以下部分描述了ParallelRaft的Ack-Commit-Apply步骤是如何优化的,以及如何维护必要的一致语义。
乱序执行,怎么保证新版本的数据不会被旧版本数据覆盖?换句话说,apply某个数据时,怎么保证不会覆盖与之有冲突的还未收到的数据。
如果某个范围的写入与其它的写入没有重叠,那么这些日志就没有冲突,可以以任意顺序执行。否则,冲突的写入操作必须按照顺序来执行。这样就保证了新修改的数据不会被旧的修改操作覆盖。
1.1 乱序的确认Ack
在接收到从leader复制的日志条目后,Raft follower将不会确认它,直到之前的所有日志条目被持久存储,这引入了额外的等待时间,并且当有大量并发I/O写入执行时,平均延迟会显着增加。然而,在ParallelRaft中,一旦日志条目被成功写入,follower可以立即确认它。这样可以避免额外的等待时间,从而优化平均延迟时间。
一旦日志复制成功,follower就给leader返回ACK。这样减少了平均延迟时间,因为不用等前面的日志。
不完全准确,这里的“乱序”并不是绝对的,最终还是要确定一个顺序。在“乱序”达到一定程度时,还是要等待前面的日志。
1.2 乱序的提交Commit
Raft的leader按顺序提交日志条目,一个日志题目在其版本之前的日志条目提交之前,该日志条目不能提交。而在ParallelRaft中,日志条目可以在大多数副本被确认后立即提交。这种提交语义对于那种通常不像TP系统
(Transaction Processing,事务处理系统)那样保证强一致性语义的存储系统是可以接受的。例如,NVMe不检查读写命令的LBA来确保并发命令之间的任何类型的顺序,也不能保证这些命令的完成顺序[13]。
新的日志条目提交后不能马上apply,如果其之前存在冲突的日志条目,则需要先将当前日志条目添加到Pending List延迟列表中,当之前存在冲突的日志条目被apply后,方能将当前日志条目从pending list中移出,并apply。
某个日志收到大多数follower返回的ACK之后,leader就提交。
1.3 Apply带空洞的日志(Apply with Holes in the Log)
作为Raft,所有日志条目都按照严格的顺序应用,因为它们被记录在ParallelRaft中,因此数据文件在所有副本中是一致的。然而,对于乱序的日志复制和提交,ParallelRaft允许在日志中存在空洞。在缺少之前的日志项的情况下,如何安全地应用日志项?这给ParallelRaft带来了挑战。
因为日志不一定是按照顺序写入的,那么肯定会有些场景出现空洞。怎么保证日志有空洞时,apply的正确性?
ParallelRaft在每个日志条目中引入了一种名为look behind buffer的新颖数据结构来解决这个问题。look behind buffer包含由前N个日志条目(log entries)修改的LBA(Logical Block Address,逻辑块地址),即该日志条目前的N个日志条目的修改(未被持久的)记录,因此一个look behind buffer充当在日志log中可能存在的空洞上构建的桥梁(跨过空洞)。N是这座桥的跨度,这也是允许的最大日志空洞尺寸。请注意,尽管日志中可能存在几个空洞,但所有日志条目的LBA摘要(LBA Summary)总是完整的,除非存在尺寸大于N的空洞。
通过这种数据结构,Follower可以判断日志条目是否冲突,这意味着由该日志条目修改的LBA与一些先前但缺失的日志条目重叠。与任何其他条目不冲突的日志条目可以安全地应用,否则应该将它们添加到挂起列表(pending list)中,并在检索到缺失条目后回复。根据我们在使用RDMA网络的PolarFS中的经验,N设置为2对于其I/O并发性来说已经足够好了。
基于上述乱序执行方法和规则,可以成功实现所需的数据库存储语义。此外,通过在ParallelRaft中消除不必要的串行限制,还可以缩短多副本并发写的延迟。
说人话:ParallelRaft引入了一个新的数据结构:look behind buffer。每个日志中都有一个这样的数据结构,look behind buffer包含前面N条日志修改的逻辑块地址(Logical Block Address),这样的话,look behind buffer就像一个日志空洞上的桥。N是这个桥的长度,就是允许出现的最大空洞。
注意虽然日志中可能存在多个空洞,所有日志条目(log entries)的逻辑块地址汇总信息总是完整的,除非有空洞比N大。
follower可以通过这个结构确定某个日志条目(log entry)是否有冲突,是指与在这个日志条目前面的,但是还未收到的日志条目修改的逻辑块地址是否有重叠(查看该日志条目之前的日志条目是否有被修改,如果有被修改但还没持久,就不能被新的修改所修改)。不与其它日志冲突的可以安全的apply,否则就加到一个pending列表中,稍后再apply。
2.Leader选举
在进行新的leader选举时,ParallelRaft可以像Raft一样选择具有最新term和最长日志条目(log entries)的节点。在Raft中,新选出的leader包含了之前term中所有已提交的条目(entries)。然而,在ParallelRaft中选出的leader最初可能不会满足这个要求,因为日志中可能存在空洞。
`由于Parallel Raft允许一定程度上的日志空洞与乱序执行,在选举中胜出的candidate实际上是不一定具有所有的集群已提交的日志的,这时候,为了得到集群中所有的已提交的日志,leader candidate需要预先经过一个merge的阶段`
因此,在开始处理选举请求之前,需要一个额外的合并阶段,以使leader拥有所有已提交的条目(committed entries)。在合并阶段结束之前,新选出的节点只是leader候选者,在合并阶段结束后,它拥有所有已提交的条目(committed entries),成为真正的leader。在合并阶段,leader候选者需要合并来自集群(仲裁)其他成员中它未见过的条目(unseen entries)。在此之后,leader将开始向集群(仲裁)提交先前term中的entries,这与Raft相同。
在合并条目时,ParallelRaft也使用与Raft类似的机制。具有相同term和索引(log index)的条目(entries)将被承诺为相同的条目。有几种异常情况:
对于一个已提交(committed)但该leader候选者缺失的条目(不在该leader候选者上),leader候选者总能从至少一个follower候选者中找到相同的已提交条目,因为该已提交的条目已被集群(仲裁)的大多数接受。
对于一个没有在任何candidate上提交(not committed)的条目,如果该条目也没有保存在任何candidate上(即没有被commit也没有被save),则leader可以安全地跳过该日志条目,因为根据ParallelRaft或Raft机制,它之前无法提交。
如果一些candidate保存了这个未提交的条目(具有相同的索引但不同的term),那么leader候选者选择具有最高term的条目版本,并将该条目识别为有效条目。因为:
- ParallelRaft的合并阶段必须在新的leader可以为用户请求服务之前完成,这决定了如果将一个条目entry设置为较高的term,具有相同条目索引的较低的term必须之前没有提交not committed过,并且较低的term必须从未参加过以前成功完成的合并阶段,否则较高的term不能具有相同的索引。
- 当系统崩溃时,有一个未提交的条目保存在一个候选者中,这个条目的ACK信号可能已经发送给前leader并回复给用户,所以我们不能简单地放弃它,否则可能会丢失用户数据。(更准确地说,如果失败节点的总数加上具有此未提交条目(具有相同索引的这些条目的最高term)的节点的总数超过了同一集群(or 仲裁)中的其他节点的数量,那么这个条目可能已被前leader提交,因此,为了用户数据的安全,我们应该提交。)
以具有3个副本的情况为例,图5显示了领导者选举的过程。
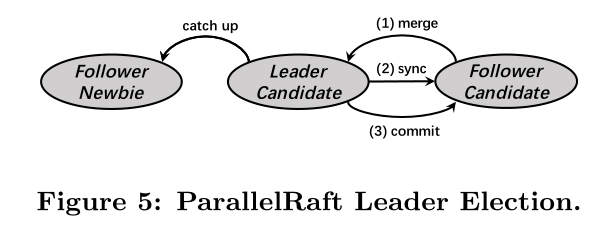
首先,follower候选人将其本地日志条目发送给leader候选人。leader候选者接收这些条目并与自己的日志条目合并。其次,leader候选人将状态同步到follower候选人。之后,leader候选人可以提交所有条目,并通知follower候选人提交。最后,leader候选人升级为leader,follower候选人也升级为follower。
使用上述机制,所有提交的条目都可以被新的leader恢复,这意味着ParallelRaft不会丢失任何提交状态。
在ParallelRaft中,一个checkpoint是不定时进行的,检查点之前的所有日志条目都应用于数据块(LBA)(即被committed且apply的),并且检查点允许包含在检查点之后提交的一些日志条目。为简单起见,检查点之前的所有日志条目都可以被视为已修剪(pruned),尽管在实践中它们会保留一段时间,直到资源不足或达到某个阈值。
在我们的实际实现中,为了Catch Up实现,ParallelRaft选择具有最新checkpoint的节点作为leader候选者,而不是具有最长日志的节点。在合并阶段,很容易看到新的leader在开始服务时达到相同的状态。因此,这种选择不会影响ParallelRaft的正确性。
checkpoint
ParallelRaft会不时地做checkpoint,checkpoint会记录一个当前系统的快照(snapshot),所有checkpoint之前的日志条目都已经apply到了数据块上,checkpoint允许包含checkpoint之后的日志条目(文中没有解释为什么,也没有介绍怎么处理的)。在实际实现中,ParallelRaft会选择有用最新checkpoint的节点作为主,而不是拥有最新日志条目的节点,原因就是catch-up的实现(为了让follower更容易的追上leader的状态)。在merge阶段拥有最新checkpoint的节点更容易处理,因为不需要处理checkpoint之前的日志条目(就是checkpoint越新,相对来说需要做merge的日志条目就越少)。
3.Catch up 追赶机制
当一个滞后的follower想要跟上leader的当前数据状态时,它将使用fast-catch-up或streaming-catch-up来重新与leader同步。使用哪一个取决于follower的状态有多陈旧。fast-catch-up机制是当leader和follower之间的差异相对较小时,为他们之间的增量同步而设计的。但follower可能远远落后于leader,例如,follower已经离线好几天了,所以完全的数据重新同步是不可避免的,因此,PolarFS提出了一个名为streaming-catch-up的方法来完成这个任务。
上图给出了重新同步开始时leader和follower的不同情况。在case1中,leader的检查点比follower的最新日志索引更新,并且它们之间的日志条目将被leader修剪pruned。因此,快速赶上不能处理这种情况,而应该使用流赶上。案例2和案例3可以通过快速追赶来解决。
在以下情况下,我们总是可以假设leader的检查点比follower的更新,因为如果不满足这个条件,leader可以立即建立一个比其他任何检查点都更新的检查点。检查点之后的日志条目可以分为四类:已提交并应用、已提交但未应用、未提交和漏洞。
Fast-Catch-Up
Follower在其检查点之后可能会有漏洞,这些漏洞将在快速追赶期间被填补。首先,再次利用look-behind-buffer填充follower检查点和leader检查点之间的漏洞,通过这个漏洞我们可以找到所有缺失修改的LBAs。这些漏洞是直接通过复制leader的数据块来填补的,这些数据块包含比follower的检查点更新的数据。其次,follower也通过从leader的日志块中读取块上的数据来填充leader的检查点之后的漏洞。
在case3中,follower可能包含一些来自旧term的未提交日志条目。与Raft一样,这些条目被修剪,然后将按照上述步骤进行处理。
streaming-catch-up
在streaming-catch-up中,比leader检查点早的日志历史对于完全的数据重新同步是无用的,并且检查点之后的数据块和日志条目的内容都必须用于重建状态(rebuild state)。在复制块(chunk)时,整个块被分成一个个128KB的小块(pieces),并使用许多小任务(small tasks),每个任务只同步单个128KB的块。我们这样做是为了建立一个更可控的重新同步。进一步的设计动机将在第7.3节讨论。
fast-catch-up(增量同步):follower检查点与leader检查点之间的日志条目已被提交,但存在空洞,由于需要避免leader的日志条目将follower的日志条目覆盖,所以需要leader先向follower发送带有look-behind-buffer的日志条目去检查follower所缺少的日志条目,然后再复制对应的数据块给follower。而对于leader检查点之后的空洞,由于这些日志可能还尚未提交,所以可以直接从leader的日志中复制过去。
streaming-catch-up(全量同步):由于比leader检查点还早的日志条目是已经被提交应用的,不需要小心覆盖问题,所以可以直接将leader检查点之前的数据直接复制给该follower。
4.ParallelRaft的正确性
Raft保证了协议正确性的以下属性:选举安全、Leader Append-Only、日志匹配、Leader完整性和状态机安全。很容易证明ParallelRaft具有选举安全、Leader Append-Only和日志匹配的属性,因为ParallelRaft根本没有改变它们。
ParallelRaft的乱序确认(commitment)引入了与标准Raft的关键区别。ParallelRaft日志可能缺少一些必要的条目。因此,我们需要考虑的关键场景是,新当选的leader应该-目,重新确认这些条目是否应该提交,然后在必要时在quorum中提交它们。在5.3节的合并阶段之后,Leader完整性得到了保证。此外,如5.2节所述,在数据库的PolarFS中乱序提交是可以接受的。
然后我们将证明乱序应用不会违反状态机安全属性。尽管ParallelRaft允许节点独立地进行无序apply,但由于look-behind-buffer(第5.2节),冲突的日志只能按严格的顺序apply,这意味着状态机(数据+提交的日志条目)在同一quorum中的所有节点上将彼此一致。有了所有这些属性,ParallelRaft的正确性就得到了保证。
5.实验
我们做了一个简单的测试来展示ParallelRaft如何提高I/O并发性。图7显示了当I/O深度从1到32以及单个FIO作业时Raft和ParallelRaft的平均延迟和吞吐量。这两种算法都是使用RDMA实现的。开始时的细微性能差异可以忽略不计,因为它们是独立实现的不同软件包。随着I/O深度的增加,两种协议之间的性能差距越来越大。当I/O深度增加到32时,Raft的延迟大约是ParallelRaft的2.5倍,IOPS(IO per second)不到ParallelRaft的一半。值得注意的是,当I/O深度大于8时,Raft的IOPS会大幅下降,而ParallelRaft将整体保持在稳定的高水平。结果证明了我们提出的优化机制在ParallelRaft中的有效性。乱序ACK和提交提高了I/O并行性,这使得PolarFS即使在繁重的工作负载下也能保持卓越和稳定的性能。